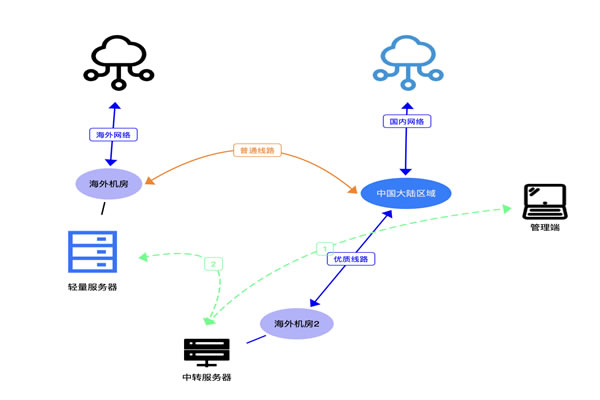
vultr新加坡机房怎么样在多地区部署中的联通性评估
本文总结了在跨国或跨区域部署时,评估和优化vultr新加坡机房联通性的关键点:从如何测量延迟与丢包、哪个网络环节最易成为瓶颈,到为什么方向性路由会影响体验,以及怎么用监测、DNS/流量调度与多路径冗余降低风险,给出实操级别的检查与优化建议,便于在多地区部署中取得稳定连通与可预测性能。
在哪里可以获取延迟与链路质量的实测数据?
要评估联通性,首要是有数据来源。可以使用远端节点的ping、traceroute、mtr等工具做端到端测试;利用第三方测站如RIPE Atlas、Speedtest、CloudHarmony或各大云厂商的Looking Glass查询路由和时延;另外从目标用户或自建探针(分布在各省/国家)收集TCP连接建立时长、抖动与丢包率,才能得到真实的用户感知数据。
哪个环节(运营商/IX/海缆)对新加坡机房的联通性影响最大?
对连接到新加坡的路径影响最大的是骨干运营商的中转与本地交换点(如新加坡主要IXP/Equinix点),其次是出发地的上游运营商与最后一公里。在亚洲区域流量中,NTT、Singtel、PCCW、Telstra 等提供的中转能力和对等策略会显著影响时延与丢包;跨洋流量还受海底电缆容量与运维状态影响。因此评估时要看端到端的ASN与中转链路。
为什么路由方向(出/入)会导致不同体验?
路由不对称是常见问题:从用户到机房的路径和返回路径可能走不同的中转网络,这会带来延迟差异和丢包点不同的情况。部分运营商对入站或出站流量的带宽与优先级处理不同,某条链路在单向出现拥塞时会影响TCP吞吐与重传表现。评估时必须分别检测双向性能,并关注BGP策略与对等关系。
怎么在中国内地到新加坡的链路上做现实体验评估?
建议分省/省会做分层测试:在若干代表性城市(北上广深、沿海与内陆)跑ICMP、TCP握手、HTTP/HTTPS请求以及大文件下载;同时用mtr查看每跳丢包点;记录峰值与非峰值时间段的数据;对比不同运营商出站的结果以判断是否与特定ISP相关。若有需要,可使用SLA级链路监控并设报警。
如何在多地区部署中提升vultr新加坡机房的联通性?
提升方案包括:1)在关键区域放置边缘节点或使用CDN以减少往返时延;2)采用智能DNS/全局流量调度,根据延迟与可用性做就近或最优路由;3)多链路与多云冗余,通过不同云或不同提供商降低单点故障;4)对重要会话使用会话保持或会话迁移策略,减少重连损耗;5)持续监控并依据数据调整流量策略。
多少延迟与丢包是可以接受的判断标准?
经验性阈值:在亚洲区域,单向延迟<50ms通常被视为良好,50–120ms为可接受,>150–200ms会影响交互类应用;丢包率方面,<0.5%可认为理想,0.5–1.5%需要关注,>2%会显著影响TCP性能和用户体验。判定应结合业务类型(实时音视频、交互、批量传输)来决定可接受范围。
哪里最容易出现瓶颈,应如何规避?
常见瓶颈在:出/入网运营商拥塞点、IXP对等不畅、服务器实例的网络带宽配额与虚拟化抖动、以及海缆故障或维护窗口。规避方法包括选择带宽与喷发能力更好的实例类型、向上游申请更佳对等、使用多链路与备用路径、并在运营商发生拥塞时快速切换流量到备用区域或CDN。
怎么在多地区部署中设计容灾与流量分配策略?
推荐采用多活或主备架构:多活结合全局负载均衡(基于健康检查与延迟判定)能提升可用性;主备则在主节点故障时通过DNS/Anycast/负载平衡切换流量。数据库层面选用跨区域复制与延迟优化方案;对会话敏感的服务应设计会话粘性与回退机制。并通过自动化检测与脚本化切换降低人工误差。
-

新加坡服务器托管价格解析及性价比分析
问题一:新加坡服务器托管的价格一般是多少? 新加坡服务器托管的价格因服务商、服务器类型、带宽、存储空间等因素而异。一般来说,新加坡服务器的基础价格大约在每月50到200美元之间。 VPS(虚拟专用服务器)通常在每月20到100美元,而独立服务器的价格则可能高达每月300美元甚至更高。具体价格需要根据用户的需求和选择的服务套餐来确定。 问题二:影响新2025年8月24日 -

新加坡母鸡服务器云主机:高效稳定的网站托管选择
在当今数字化时代,拥有一个高效稳定的网站托管选择对于企业的成功至关重要。新加坡母鸡服务器云主机是一个值得考虑的选择。本文将介绍新加坡母鸡服务器云主机的优势和特点。 新加坡母鸡服务器云主机是一种基于云计算技术的高性能托管方案。它利用新加坡的先进网络基础设施和高速互联网连接,为用户提供稳定、快速的网站托管服务。 1. 高性能 新加坡母鸡2025年2月11日 -

监控与告警在移动 新加坡 无服务器 环境中的实施方法
对于部署在新加坡区域、面向移动用户的无服务器架构,主要挑战包括:短生命周期函数导致的可观测性缺失、异步事件与大量短连接造成的指标稀疏、跨区域与边缘节点的日志聚合复杂性,以及移动网络波动带来的噪声报警。再加上新加坡对数据主权与低延迟的需求,这些都会影响监控设计。 要解决这些挑战,应重点关注函数跟踪、端到端事务链路追踪、以及采样策略。设计上要结合日志、2026年4月15日 -

新加坡站群多IP服务器部署方案与性能优化实践案例分析
本文总结了在新加坡地区构建和优化新加坡站群的关键实践,从IP规划、节点选型、网络拓扑到负载均衡与缓存优化,结合自动化部署与运行维护策略,提供可复制的实战步骤与注意事项,帮助工程团队在保证稳定性与合规性的前提下提升访问性能与IP资产利用效率。 哪个IP分配策略更适合站群部署? 在构建多IP服务器站群时,合理的IP分配决定稳定性与可控性2026年7月19日 -

如何判断新加坡高防云服务器的性能与安全性
新加坡高防云服务器因其优越的性能和安全性而备受青睐。为了确保您选择的云服务器能够满足需求,了解如何判断其性能与安全性显得尤为重要。本文将为您提供详细的步骤操作指南,帮助您全面评估新加坡高防云服务器的各项指标。 1. 确定服务器的性能指标 在评估新加坡高防云服务器的性能时,首先需要关注以下几个关键指标: - C2025年9月5日 -

云顶之弈新加坡服务器推荐
云顶之弈新加坡服务器推荐 云顶之弈是一款热门的自走棋游戏,玩家们在游戏中通过选择并搭配不同的英雄和装备来组建强大的战队。而要保证游戏体验的流畅与稳定,选择一个合适的游戏服务器非常重要。在这篇文章中,我们将向大家推荐云顶之弈的新加坡服务器。 新加坡作为亚洲的科技中心,拥有先进的网络设施和强大的服务器基础设施。选2025年2月25日 -
GTA5新加坡服务器的延迟表现与体验
GTA5新加坡服务器的延迟表现与体验 在玩GTA5时,服务器的延迟表现是影响游戏体验的关键因素之一。新加坡服务器因其地理位置和网络条件,成为了许多玩家的选择。本文将详细介绍新加坡服务器的延迟表现及如何优化您的游戏体验。 以下是详细的操作步骤和指南,帮助玩家们更好地理解和体验GTA5的游戏乐趣。 1. 检测当前延迟 在选择新加坡服务器之前,2025年8月28日 -

新加坡服务器托管的全面解析与实用指南
在全球化的今天,选择合适的服务器托管服务对于企业的在线业务至关重要。新加坡因其优越的地理位置和稳定的网络环境,成为了许多企业的首选。本文将详细解析新加坡服务器托管的各个方面,并提供实用指南,帮助您顺利完成服务器托管的过程。 以下是本文的详细目录: 1. 了解新加坡服务器托管 新加坡服务器托管是指将您的网站或应用程序托管在新加坡的服2025年8月18日 -

如何选择适合您的新加坡服务器
在选择适合您的新加坡服务器之前,您需要考虑一些关键因素,以确保您的网站或应用程序能够在新加坡地区提供高性能和稳定的服务。本文将介绍一些选择新加坡服务器的要点和建议。 首先,您需要明确服务器的主要用途和需求。您是打算托管网站还是应用程序?您需要多少存储空间和带宽?了解您的需求将有助于您在选择服务器时做出明智的决策。 性能和可靠性是选择服2025年1月14日